记第一次尝试使用node进行爬虫的经历
简介
这是我第一次尝试爬虫,也是第一次使用node.js爬虫,有啥不正确的望各位大佬多多指教。
本实验是基于nodejs中,使用cheerio模块实现简单爬取网站所需信息,因为在次实例中(本次实例的网址)需要做到写入文件以及启动我们自己的服务(可能不用)和创建http请求,所以还需要用到另外三个模块,fs、express以及axios
模块安装
1 | npm init -y #跳过向导,快速生成package.json说明书文件 |
axios简介
Axios 是一个基于 promise 的 HTTP 库,可以用在浏览器和 node.js 中
cheerio简介
Fast, flexible & lean implementation of core jQuery designed specifically for the server.
express简介
基于 Node.js 平台,快速、开放、极简的 Web 开发框架
模块引入
在这里其实有个小插曲,一开始是想用request模块去请求目标网址,可是不知道出现何种原因,请求不了(用这个模块尝试其它网址是可以的),所以更换成了axios模块
1 | const express = require('express') |
使用
axios自带promise的使用方法,在get我们需要爬取的网址后,通过cheerio的load方法获取该页面的html结构,我们可以使用$来接收这个变量(官网就是这样写的),然后就可以用类似JQuery的方法去操作里面的元素了,这里我们需要每个学校的学校名,邮编以及联系方式,所以我们可以打开f12查看这些标签的信息,通过唯一的id名或者类名,我们就可以对该节点的子节点元素进行遍历,然后将数据存入我们准备好的txt或者其他文本文件里,之后再做进一步筛选和处理
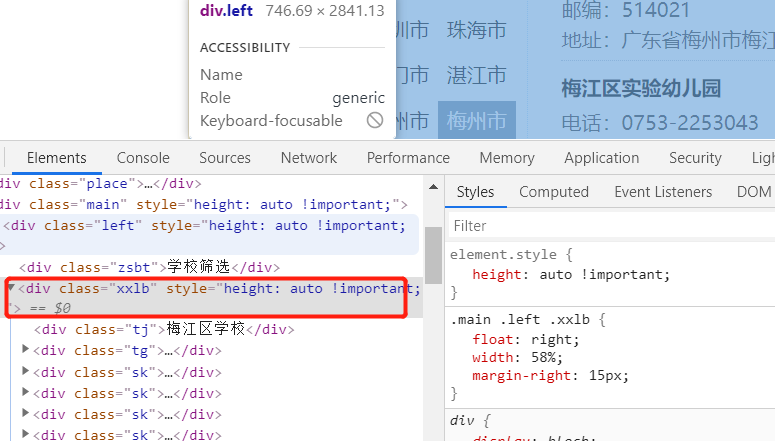
因为数据分好几页,所以在这里我首先去获取到该页面总共的页数,之后定义了一个for循环,去循环遍历每一页,再对每一页的内容进行爬取
以下为主要的爬取代码
1 | axios.get('https://www.ruyile.com/xuexiao/?a=3120') |
其它标签的内容使用同样的原理进行爬取
总结
总觉得这次写的代码有哪些欠缺(运行起来是没有问题的),或者美观度,易读性不太好,遇到的困难就是在request模块下请求不到该网址,最后想不出什么解决方法,所以也更换了模块,就当是第一次爬虫的锻炼吧(好长的路要走),也是第一次尝试用nodejs进行爬虫。
 wechat
wechat alipay
alipay

